Search and Backend
Building the platform that powers search, content, and scale for millions of shoppers

Flipp
Flipp is a leading weekly shopping app that aggregates local flyers, circulars, and coupons into a single, easy-to-use experience. By 2016, its iOS and Android apps had reached over 100 million shoppers and were used by millions of active users for everyday shopping. In 2017, Business Insider ranked Flipp #4 among the top 11 fastest-growing apps in the U.S., alongside Uber, Tinder, Lyft, and Waze, following an 850% increase in usage over two years.
Background
Grocery shopping is a universal, recurring need for families across the world, and even small savings can have a meaningful impact. Behind Flipp’s consumer facing mobile and web experience sits a large-scale backend platform responsible for ingesting, indexing, and serving millions of flyers, coupons, searches, and views every week.
As a backend and platform product manager, I worked closely with backend, search, and content teams to deliver the systems that powered this B2C product at scale. I initially joined as the Content Product Manager, owning ingestion and content workflows, and later transitioned into the Backend Product Manager role, where my focus expanded to platform reliability, scalability, and search relevance.
Within search specifically, I led initiatives to improve autocomplete and autocorrect, reduce zero-result queries, and meaningfully increase precision and recall, directly impacting discoverability, engagement, and revenue.
Internally, the team was known as “Backflipp” - a reflection of both our focus and the critical role we played in keeping the product running smoothly behind the scenes.
My Contributions
- Defined and led backend platform requirements supporting Flipp’s mobile and web experiences at consumer scale
- Led the evolution of search from a basic keyword engine toward relevance-driven discovery, defining strategy and roadmap to significantly improve search quality
- Partnered with and guided a cross-functional team of backend engineers, QA, and data scientists to deliver a highly available, performant, and scalable backend with a uniform API surface
- Launched Flipp Accounts, enabling digital coupon redemption across mobile and web platforms
- Shipped foundational features including Store Mode and dynamic Shopping Lists, simplifying and enhancing the shopping experience
- Led content ingestion and delivery systems to ensure flyer content was accurate, timely, and reliable at scale, using data-driven insights to inform product decisions
Improving Search Relevance - Crowd Curation (2015)
This project started as a hackathon idea. At the time, I wanted to see if we could meaningfully improve search relevance without taking on a massive engineering effort upfront.
Search at Flipp was still a fairly basic feature. It was powered by Sphinx, a text-based search engine, and relied heavily on keyword matching. Meanwhile, our content base was growing quickly, and millions of users depended on search to find the right flyer and deals fast. The gap was becoming obvious.
Relevance was mostly handled through manual curation. We looked at top search terms and used negative keywords to push results up or down. This approach did not scale. It was time consuming, reactive, and increasingly disconnected from how users were actually behaving. We needed a more automated, data-driven way to improve results.
That led to the idea of crowd curation.

Inspired by how platforms like Reddit surface content, the core idea was simple: let user behavior help determine relevance. If users consistently clicked on certain items for a given query, those items were likely more relevant and should be ranked higher. Click behavior became a signal, not just an outcome.
We started with a straightforward implementation. For a query like “bbq,” we compared the existing keyword-based results with results reordered using aggregated click data.
After the hackathon, we rolled this out as an A/B test in a single geography. The results were immediately promising. Users were clicking significantly more on the top-ranked results, particularly positions one through three. Exact numbers are redacted, but the directional impact was clear.
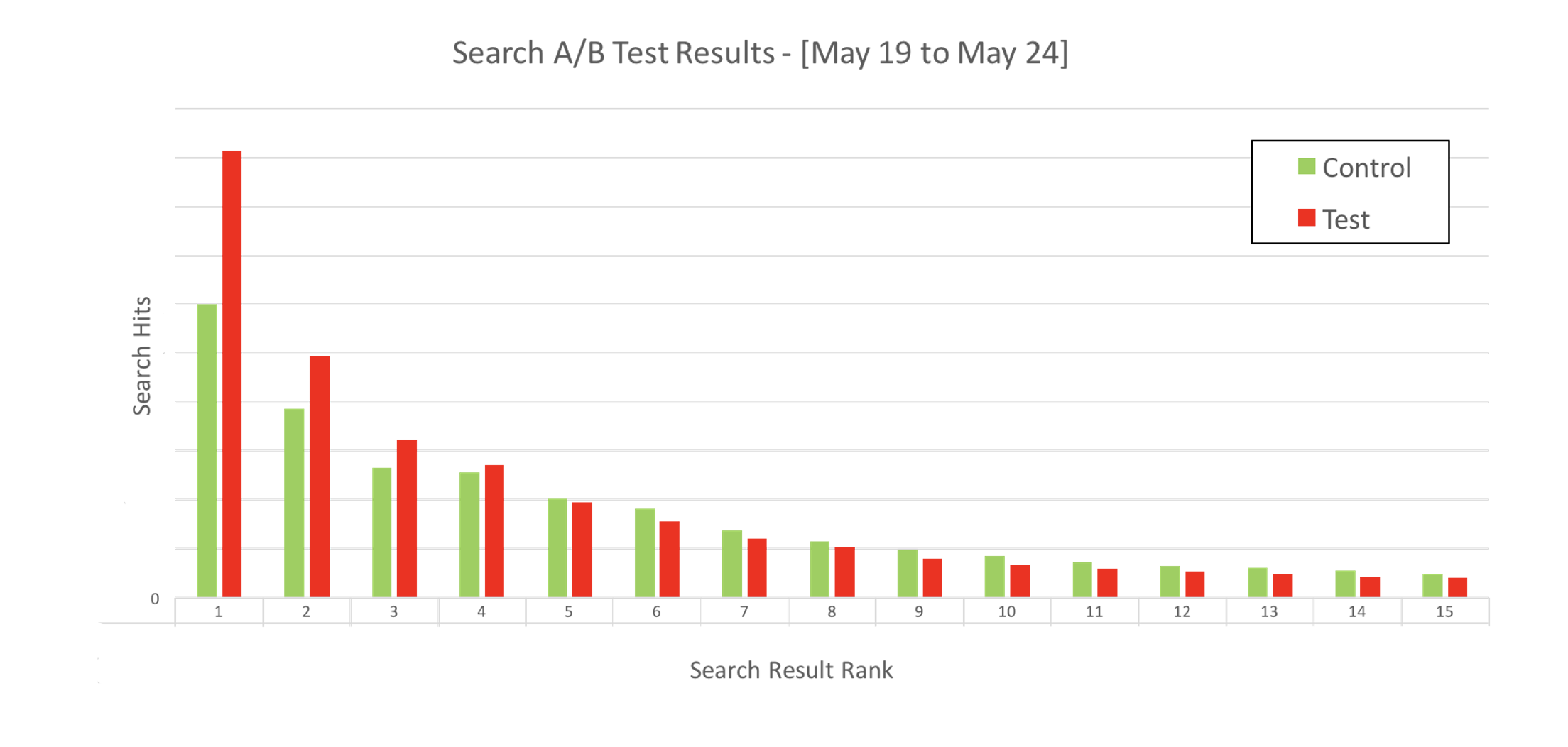
The experiment helped shift how the organization thought about search. The executive team saw firsthand that relevance could be improved by aligning ranking logic with real user behavior. This project became a catalyst for deeper investment in search.
In the months that followed, we moved away from Sphinx and invested in a more robust search stack using Solr and Lucene. We began applying machine learning and data science more systematically to relevance, moving from manual tuning toward a scalable, measurable approach to search quality.
References
How Crowd Curation Improved Our Search Quality by 27% - freecodecamp.org
Store Mode (2016)
We began by speaking with a broad set of grocery shoppers to understand where friction existed during in store shopping. While issues like parking availability and checkout lineups surfaced frequently, they fell outside our core mission of helping people save time and money on their weekly grocery trips.
A clearer and more universal pain point emerged inside the store itself. Shoppers often struggled to find specific items, especially when visiting an unfamiliar location. This led to frustration, unnecessary backtracking through aisles, hesitation to ask for help, and longer shopping trips overall.
The problem we chose to focus on was simple and concrete: when a shopper is already in the grocery store, how do they quickly find exactly what they are looking for. This framing allowed us to stay aligned with our mission while targeting a moment of high friction and immediate user value.
Solution
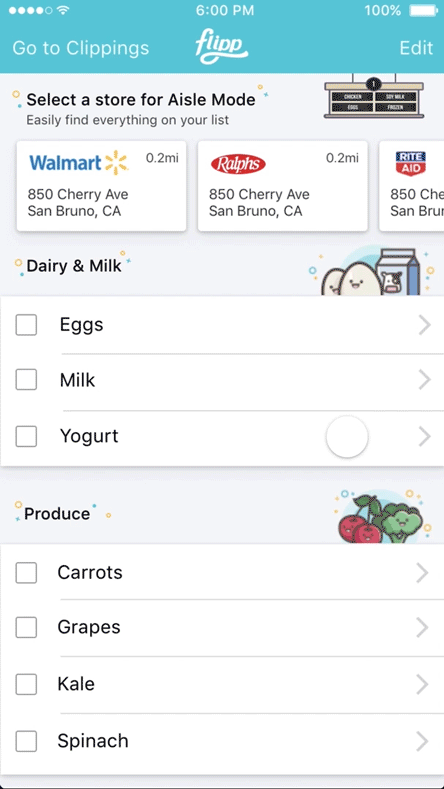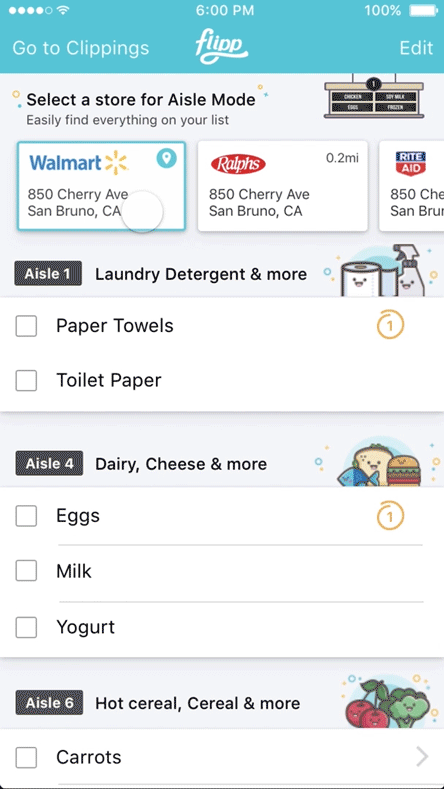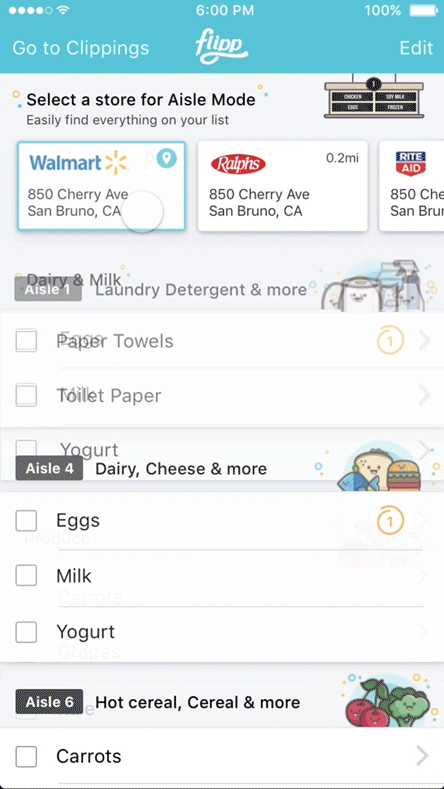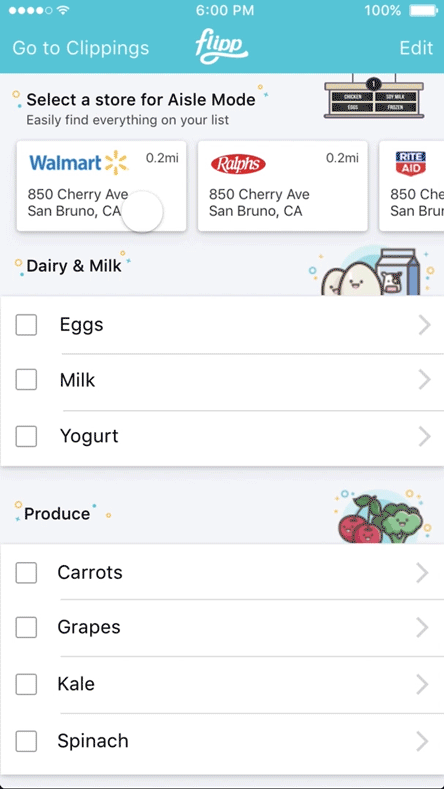
Store Mode was designed to help shoppers quickly locate items once they were inside the store. It built on the existing Shopping List experience and automatically organized items by aisle, reflecting the layout of the specific store. Shoppers could also search within the store to find where an item was located, reducing unnecessary backtracking and guesswork. By guiding users directly to the right aisles, Store Mode helped shorten trips, reduce frustration, and make in store shopping more efficient.
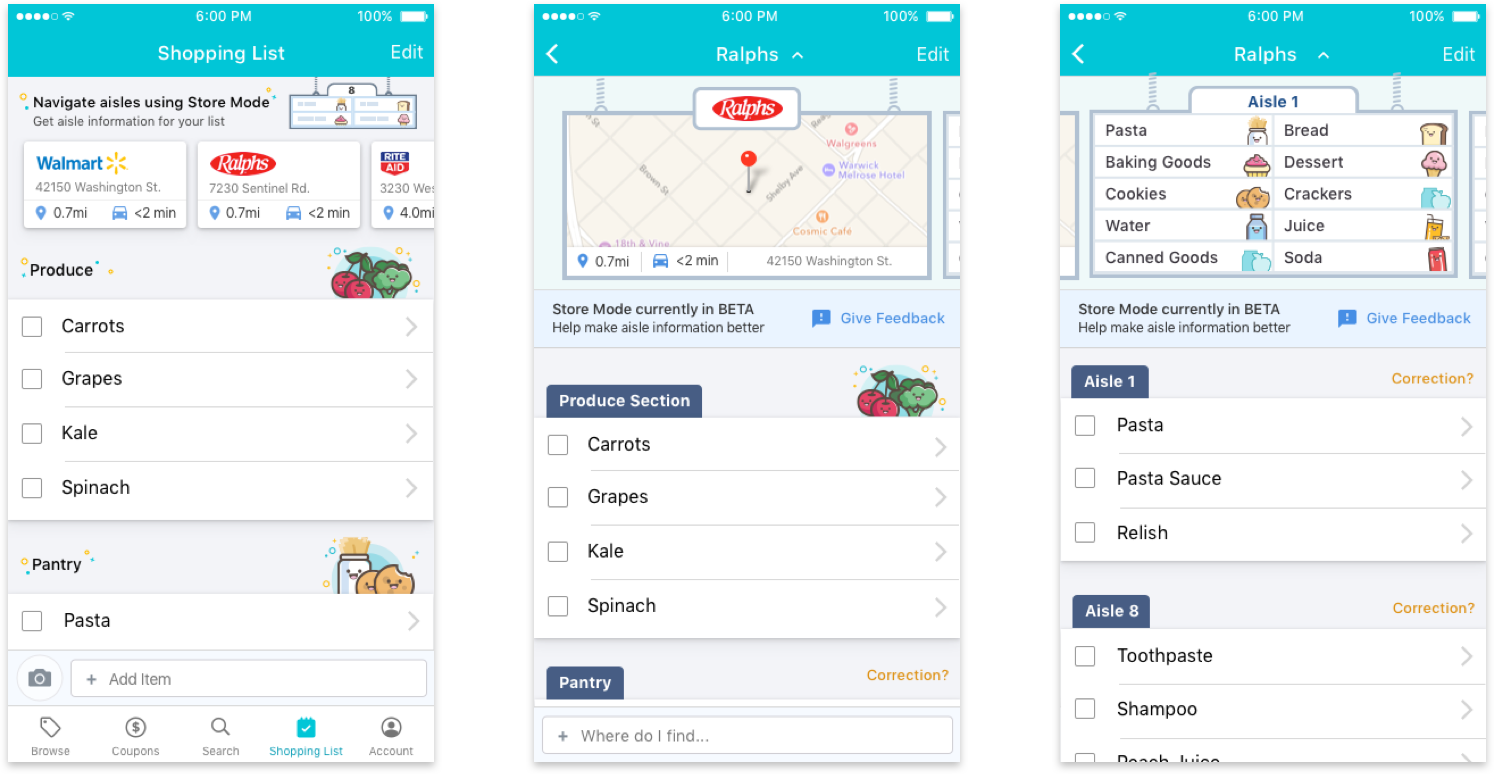 Screenshots from Store Mode (2016)
Screenshots from Store Mode (2016)
Beyond the design, building this feature required assembling and maintaining a large, high quality dataset spanning retail stores across North America. This involved sourcing aisle level data from multiple third party providers, indexing it, and continuously refining it through user feedback and operational workflows. Turning raw aisle imagery into structured, backend ready data required custom ingestion pipelines and close collaboration with an operations team that translated physical store layouts into machine readable formats.
Once this foundation was in place, we were able to match a user’s shopping list to the specific store and aisle they were visiting, enabling real time in store guidance. Delivering this experience required tight coordination across product, engineering, design, and operations, with many moving parts that had to work reliably together. While it was an expensive and ambitious experiment, the outcome was significant: within six months, aisle level coverage was live for stores across the top 50 US metropolitan areas.
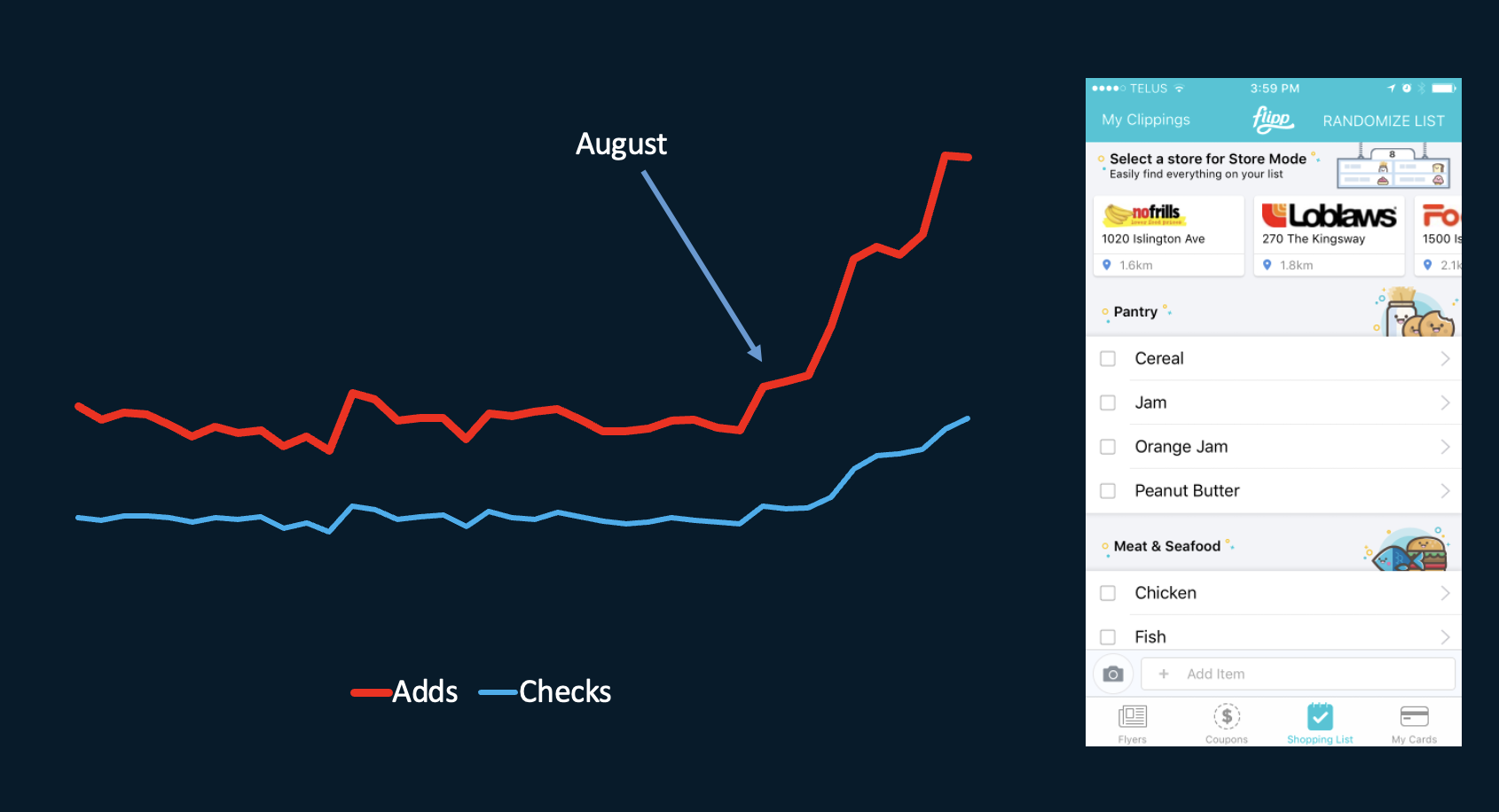 Graph showing a noticeable increase in shopping list adds and item check-offs after storemode release August of 2016.
Graph showing a noticeable increase in shopping list adds and item check-offs after storemode release August of 2016.
Today this kind of capability may seem straightforward, but in 2016 it required sustained cross functional effort and a willingness to invest deeply in infrastructure and data quality. Users who used this feature often loved it.